How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models
Abstract
Video editing and generation methods often rely on pre-trained image-based diffusion models. During the diffusion process, however, the reliance on rudimentary noise sampling techniques that do not preserve correlations present in subsequent frames of a video is detrimental to the quality of the results. This either produces high-frequency flickering, or texture-sticking artifacts that are not amenable to post-processing. With this in mind, we propose a novel method for preserving temporal correlations in a sequence of noise samples. This approach is materialized by a novel noise representation, dubbed \(\smallint\)-noise (integral noise), that reinterprets individual noise samples as a continuously integrated noise field: pixel values do not represent discrete values, but are rather the integral of an underlying infinite-resolution noise over the pixel area. Additionally, we propose a carefully tailored transport method that uses \(\smallint\)-noise to accurately advect noise samples over a sequence of frames, maximizing the correlation between different frames while also preserving the noise properties. Our results demonstrate that the proposed \(\smallint\)-noise can be used for a variety of tasks, such as video restoration and editing, surrogate rendering, and conditional video generation.
Gaussian Noise Warping: a Recipe
Step 1: Think of pixels as tiny squares
Our first insight is to reinterpret pixels values not as associated to discrete points, but rather as the result of integrating some underlying, continuously defined signal over the pixel area.
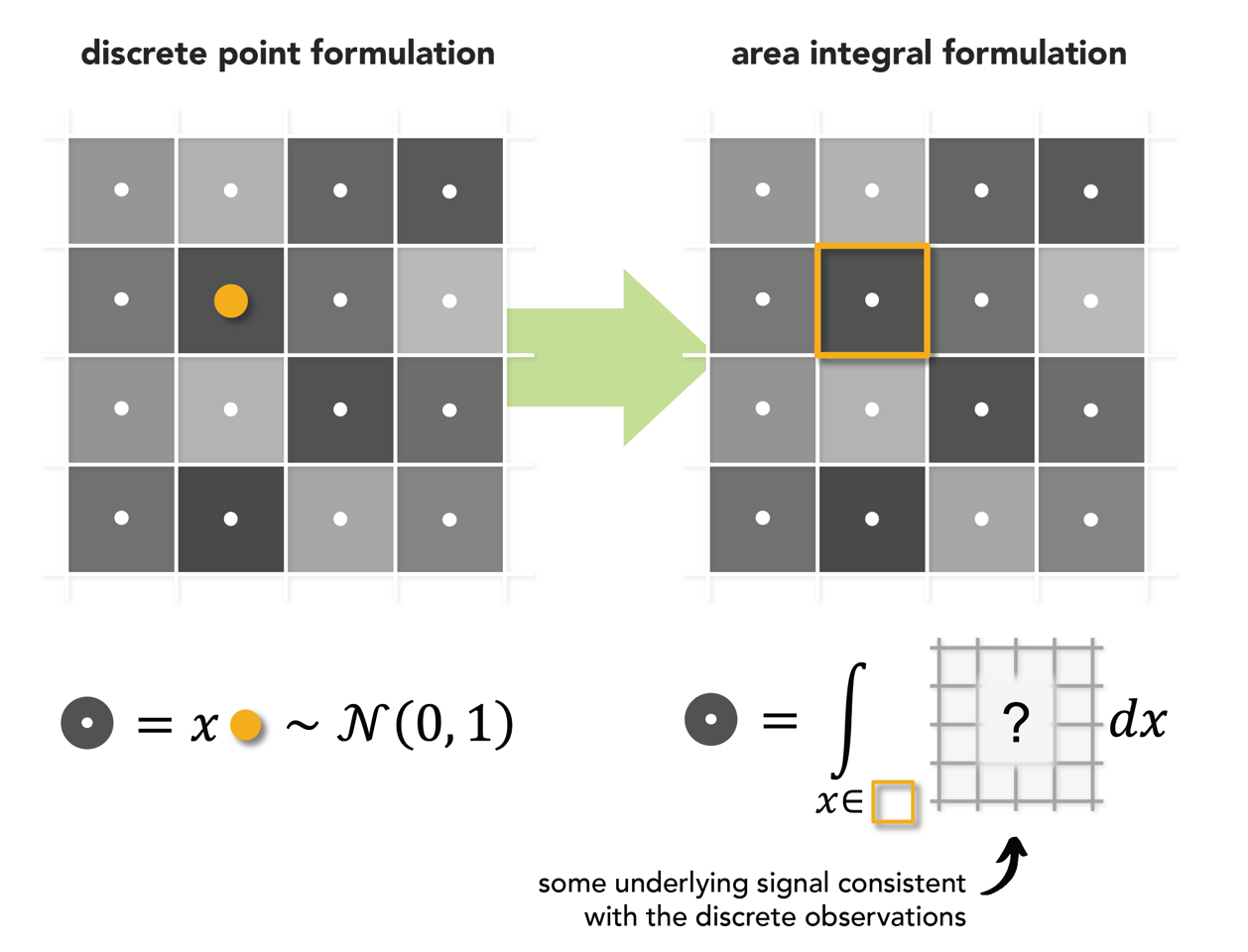
Step 2: Choose a nice underlying signal
To avoid any spatial correlation during warping, we conceptually use the reproductive property of the Gaussian distribution to recursively upsample a noise sample by subdividing pixels into smaller independent Gaussian samples. At the limit, the ideal signal is a white noise field.
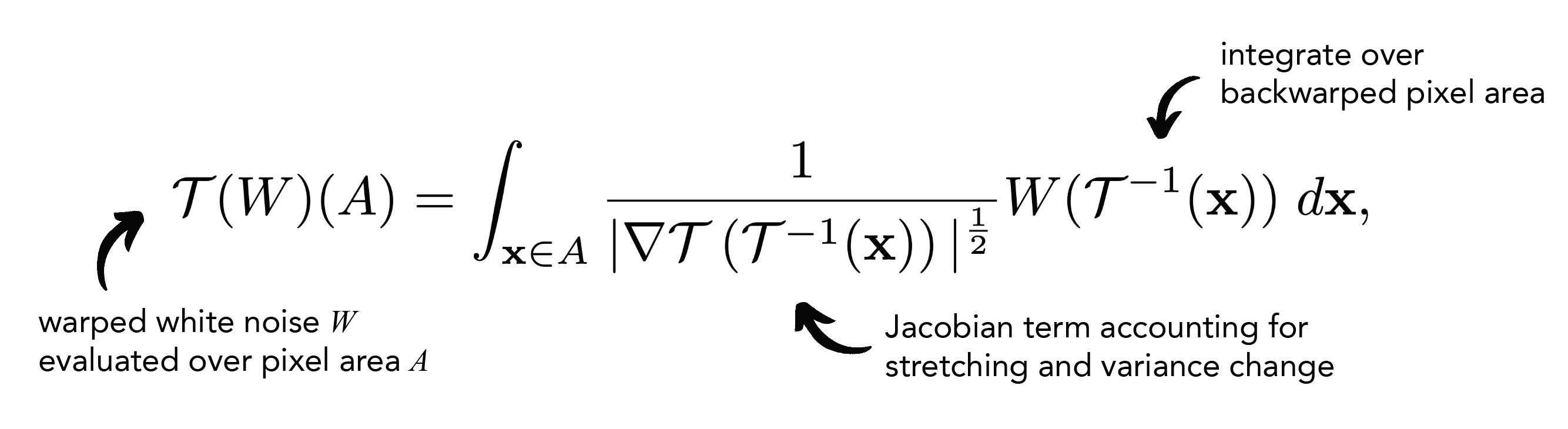
Step 3: Warp your noise!
Lastly, warping a pixel is achieved by integrating the white noise field of the previous timestep over the backwarped pixel area. This is given by our noise transport equation expressed as an Itô integral:
Noise Warping Comparison
Our method allows warping Gaussian noise with extreme deformations while still preserving its Gaussian properties. This is not achievable with standard warping and interpolation methods, as we show in the comparison below. These tend to create numerical dissipation, which destroys high-frequency details and produces blurring. Our \(\smallint\)-noise method outperforms all existing warping methods by transporting the noise perfectly while keeping its Gaussian properties.
Pause the videos at any time using the buttons in the corner and observe how \(\smallint\)-noise is indistinguishable from standard Gaussian noise despite being temporally-correlated.
Bilinear
Bicubic
Nearest Neighbor
\(\smallint\)-noise (Ours)
Realistic Appearance Transfer with SDEdit
Random Noise
Fixed Noise
PYoCo (progressive) [1]
Control-A-Video [2]
Bilinear Warping
Bicubic Warping
Nearest Warping
\(\smallint\)-noise (Ours)
Video Super-resolution with I²SB
Input (low-res)
Random Noise
Fixed Noise
PYoCo (progressive) [1]
Control-A-Video [2]

Bilinear Warping
Bicubic Warping
Nearest Warping
\(\smallint\)-noise (Ours)
Input (low-res)
Random Noise
Fixed Noise
PYoCo (progressive) [1]
Control-A-Video [2]
Bilinear Warping
Bicubic Warping
Nearest Warping
\(\smallint\)-noise (Ours)
Video JPEG Restoration with I²SB
Input (JPEG compressed)
Random Noise
Fixed Noise
PYoCo (progressive) [1]
Control-A-Video [2]
Bilinear Warping
Bicubic Warping
Nearest Warping
\(\smallint\)-noise (Ours)
Input (JPEG compressed)
Random Noise
Fixed Noise
PYoCo (progressive) [1]
Control-A-Video [2]
Bilinear Warping
Bicubic Warping
Nearest Warping
\(\smallint\)-noise (Ours)
Pose-to-Person Video Generation with PIDM
Fixed Noise
Random Noise
Bilinear Warping
\(\smallint\)-noise (Ours)
Fixed Noise
Random Noise
Bilinear Warping
\(\smallint\)-noise (Ours)
Fluid Simulation Super-resolution
Condition
→
Fixed Noise
Random Noise
Control-A-Video [2]
\(\smallint\)-noise (Ours)
Condition
→
Fixed Noise
Random Noise
Control-A-Video [2]
\(\smallint\)-noise (Ours)
Condition
→
Fixed Noise
Random Noise
Control-A-Video [2]
\(\smallint\)-noise (Ours)
Integration with DeepFloyd IF
DeepFloyd IF is a state-of-the-art text-to-image diffusion model by Stability AI. It consists of a frozen text encoder and three cascaded pixel diffusion models, respectively generating 64x64 px, 256x256 px and 1024x1024 px images. We show that our \(\smallint\)-noise prior can be integrated with DeepFloyd IF. We illustrate this on two tasks: video super-resolution and video stylization.
Video super-resolution: we give a 64x64 video sample to the Stage II model and use the following prompts to guide super-resolution: "A blackswan on water, photography, 4k", "A car on a road in the mountains". We additionally apply a simple cross-frame attention mechanism to help improve temporal coherency. The results below comparing different noise priors show that the simple combination of cross-frame attention with our \(\smallint\)-noise prior significantly reduces visual artifacts when lifting DeepFloyd IF to the temporal domain.
Input (low-res)
DeepFloyd IF + Random noise
DeepFloyd IF + Fixed noise
DeepFloyd IF + \(\smallint\)-noise (Ours)
Video stylization: we experiment with DeepFloyd IF's style transfer ability on the mountain car example. In the following we show a style of an oil painting applied to the original video. Our \(\int\)-noise prior is compared to fixed and random noise, and cross-frame attention is applied (anchor frame every 10 frames). As one can see, the choice of the noise prior has a clear impact on the temporal coherence of the final results. Note that better tuning of the style transfer parameters in DeepFloyd IF is likely to further improve the stylization quality.
Input
DeepFloyd IF + Random noise
DeepFloyd IF + Fixed noise
DeepFloyd IF + \(\smallint\)-noise (Ours)
BibTeX
@inproceedings{
chang2024how,
title={How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models},
author={Pascal Chang and Jingwei Tang and Markus Gross and Vinicius C. Azevedo},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=pzElnMrgSD}
}References
[1] Ge, Songwei, et al. "Preserve your own correlation: A noise prior for video diffusion models." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[2] Chen, Weifeng, et al. "Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models." arXiv preprint arXiv:2305.13840 (2023).